回顾
为什么标红位置可以合并

最后求得的其实是一个数, 有A^T=A
为什么无解(逆不存在处理方式)
- 逆可能不存在
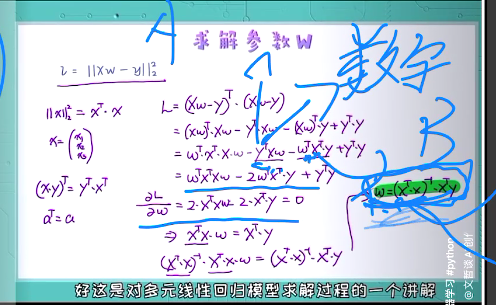
逆不存在问题如何解决

加一个人为构造项,解决行列式等于0(逆不存在)的问题
符号和数据的概念
连加和连乘(略)
其他常用符号

- 范数【1(曼哈顿距离)、2、无穷(取最大值)】

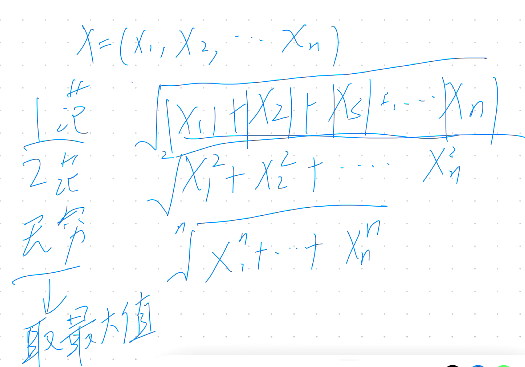
向量、矩阵、张量
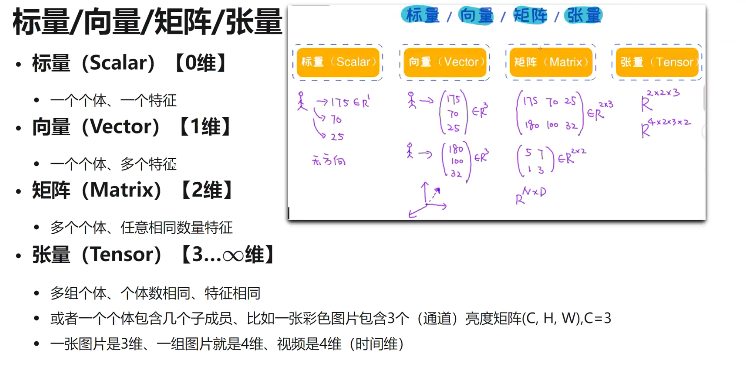
- 第一维是表示有几层
- 彩色图像的张量,R,G,B(3个通道)分别为一个2维矩阵,叠加在一起形成一个3维张量
- np.zeros和torch.tensor(数组与张量)的区别——库不一样(代码层面不同,数学意义相同)

精确率与召回率

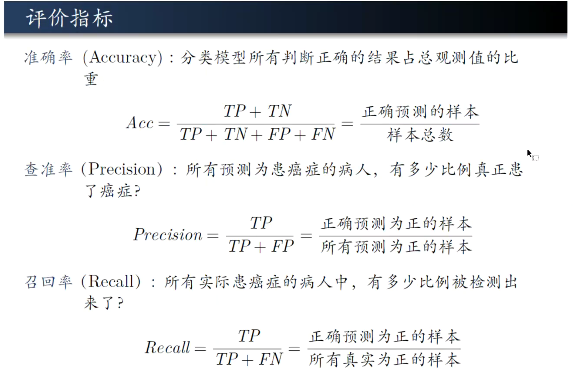
- 错杀比例和漏网比例
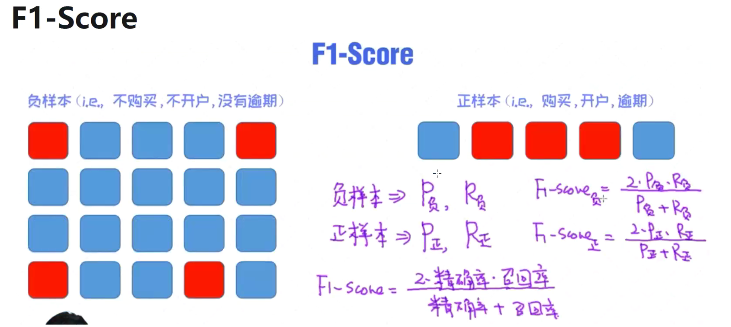
- F1综合了两个指标

- 准确率与召回率的负相关关系

- 补充,ROC曲线,AUC面积
证明逻辑回归是线性分类器(线性分类器和非线性分类器)
基础内容(什么是逻辑回归)
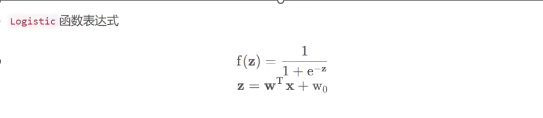
为什么逻辑回归是线性分类器
- 对于分界线上的点有以下内容(决策边界是线性表达的)

- 什么叫线性分类器——决策边界是线性表达的,是直线、平面或超平面
- 当一个问题可以用线性分类器也可以用非线性分类器时,==效果也差不多==,线性分类器计算效率很高,所以在大规模应用时可以优先选择线性分类器
- 线性分类器——拟合效果差、计算效率高
- 逻辑回归为什么是线性分类器
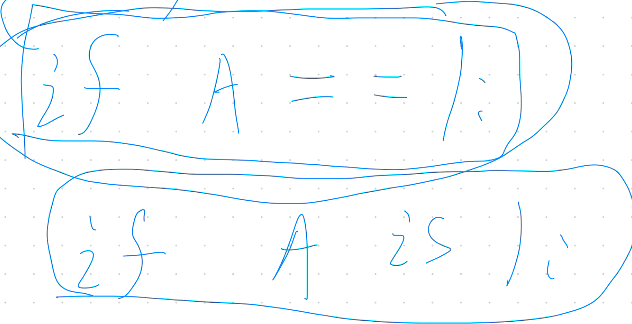
判定语句区别(内存存储问题)
"= ="用于检查两个表达式的值是否相等,它会比较两个表达式的值,如果值相等,则返回True,否则返回False。
而is运算符则用于比较两个对象是否完全相同(即比较它们在内存中的地址),如果两个表达式引用的是同一个对象,则返回True, 否则返回布尔值和空字False。因此,在Python中,对于简单的数据类型比如整数、符串等常用类型,通常使用"is”来进行比较更加高效。
所以,在if语句中,使用"= ="比较值是否相等的话,相当于比较两个变量所代表的值是否相等。而使用”is”比较的是两个变量所引用的对象是否相同
- 最终权重趋于无穷
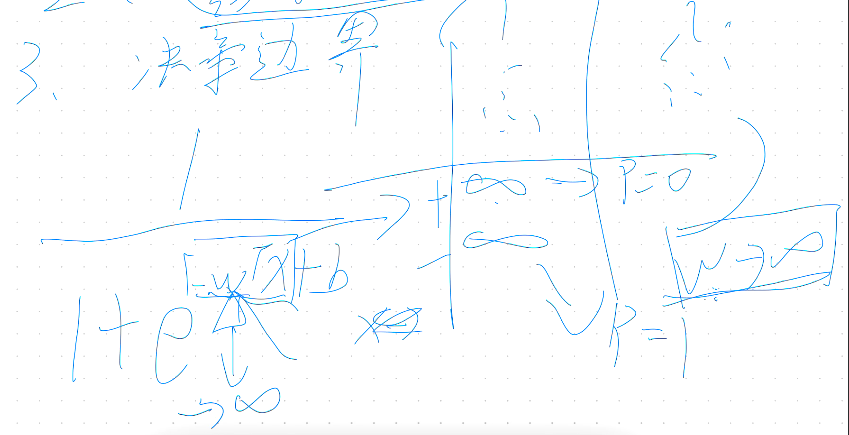
梯度下降
- 为什么是负梯度下降——向最小方向移动

随机梯度下降法

- o(1),改变样本(随机梯度下降)
- o(n),要遍历所有样本(原始梯度下降)
- 正则,防止过拟合(只影响权重,对偏执没有影响)
小批量梯度下降法(分批次计算)
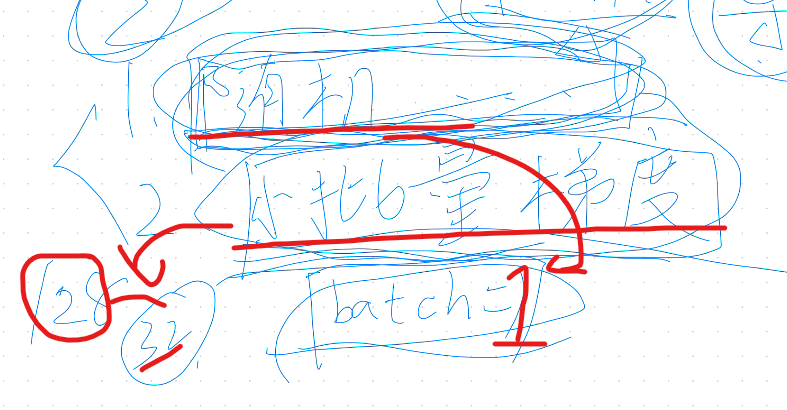
- 小批量也要引入随机概念,每次计算后要把总体打乱一次(shuffle),形成小批量+随机的计算模式
最大似然估计与最大后验估计
什么是最大似然估计(MLE)
- 由已知观测条件与观测样本推断在什么整体分布类型以及总体参数下,这些样本出现的概率最大

- 什么是参数——决定模型特性的数值
最大后验估计(MAP)
- 引入先验概率
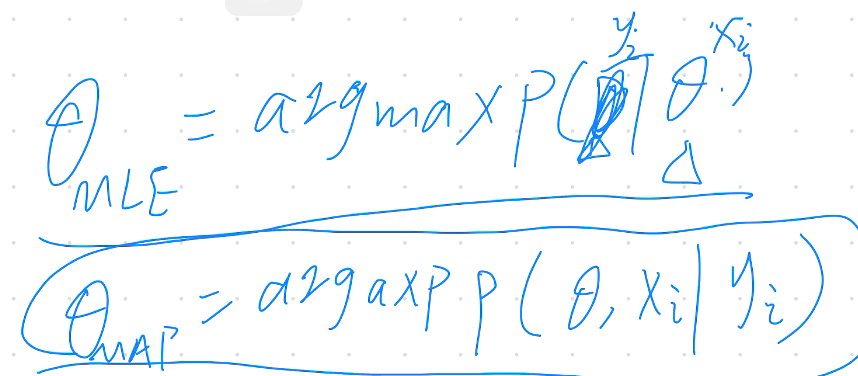
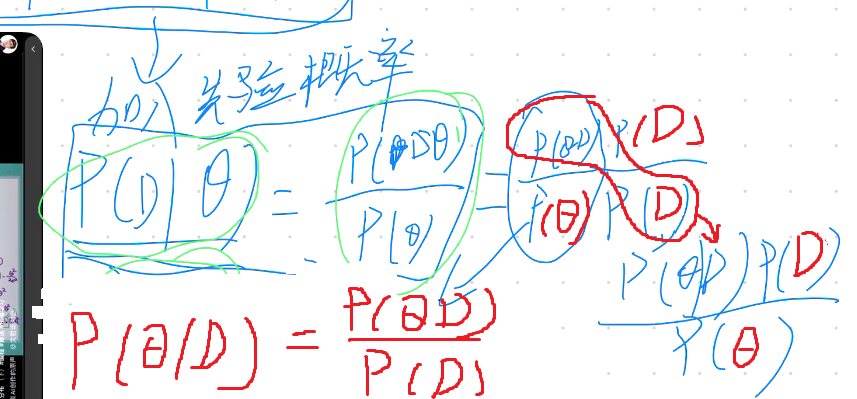

- 区别:引入先验概率
- 联系:最大似然估计是基础
先验概率

- 统计学上是如何判断斯分布与拉普拉斯分布的?
- 服从高斯分布使用L2正则化

服从拉普拉斯分布使用L1正则化
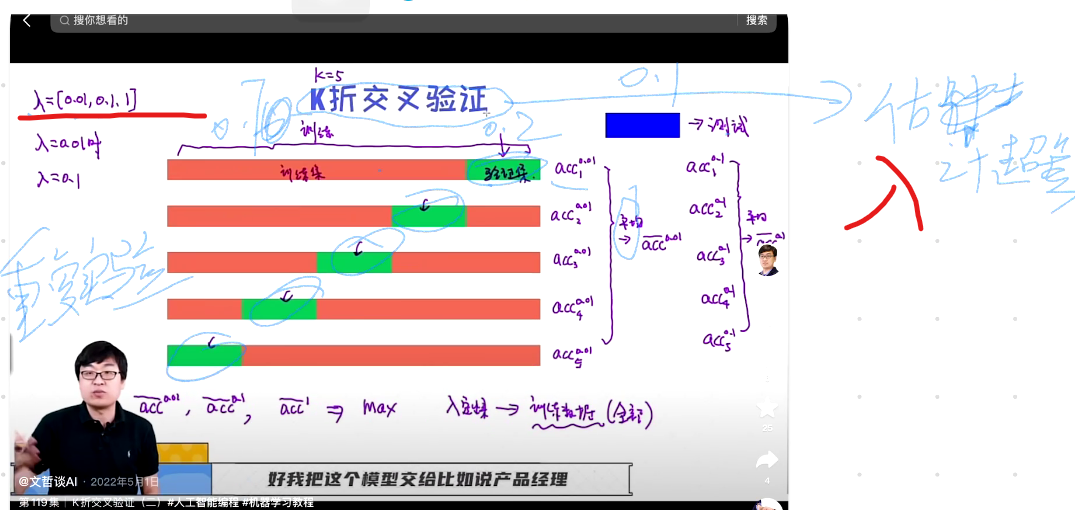
K折交叉验证
- 多次划分训练与验证集
- 为了确定超参数 lamda
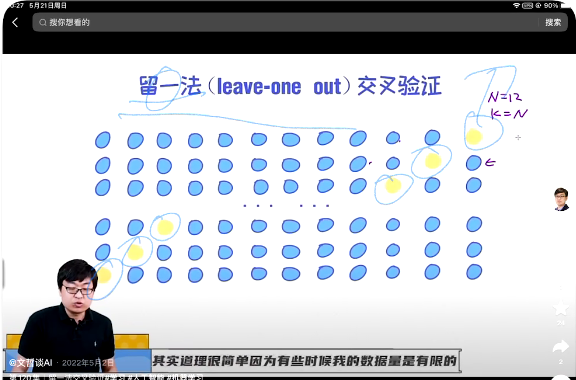
留一法交叉验证(数据少)
补充内容




